综合新闻


现在的位置:主页 > 综合新闻 >
大数据开发与管理架构完整剖析
【作者】:网站采编【关键词】:【摘要】:编辑导语:随着通信技术的发展,互联网网民规模呈现出井喷式的增长,在此背景下,通过大数据管理,挖掘其中的价值,实现用户更好的体验与服务,成为了当下研究的热点之一。本
编辑导语:随着通信技术的发展,互联网网民规模呈现出井喷式的增长,在此背景下,通过大数据管理,挖掘其中的价值,实现用户更好的体验与服务,成为了当下研究的热点之一。本文对大数据开发与管理架构进行了详细的剖析,希望对你有所启发。

一、为什么要进行大数据开发与管理
在通信技术的大力发展下,互联网、终端数字设备与传感器不断普及,进而呈现用户数量稳步增长,数据量井喷型增长。2021年中国互联网统计发展报告显示全国网民规模达10.11亿,数字化应用日渐丰富,涉及生活服务、文娱内容、医疗教育等领域,预计2025年全球每天产生的数据量将达到491EB。
在此背景下,通过管理大数据,挖掘其中的价值为用户提供更好的体验与服务成为了当下的热门研究点之一。
用户通过线上/线下行为产生的数据推动功能服务优化,更好的服务又反馈服务于用户,例如:
- 通过采集用户消费记录提取特征,计算与用户偏好匹配度更高的商品进行推荐;
- 通过分析用户群体行为特征进行未来行为发展预测等。
这样的形式让“数据”与“服务”相辅相成形成良性循环,但这两者是无法直接连通的,中间存在各种问题,例如:
- 数据来源不同、数据类型众多
- 数据质量参差不齐
- 数据可能重复或缺失
- 不同的服务需要的数据不同,如何提供数据支撑使成本最低
- 海量数据耗费存储资源
- ……
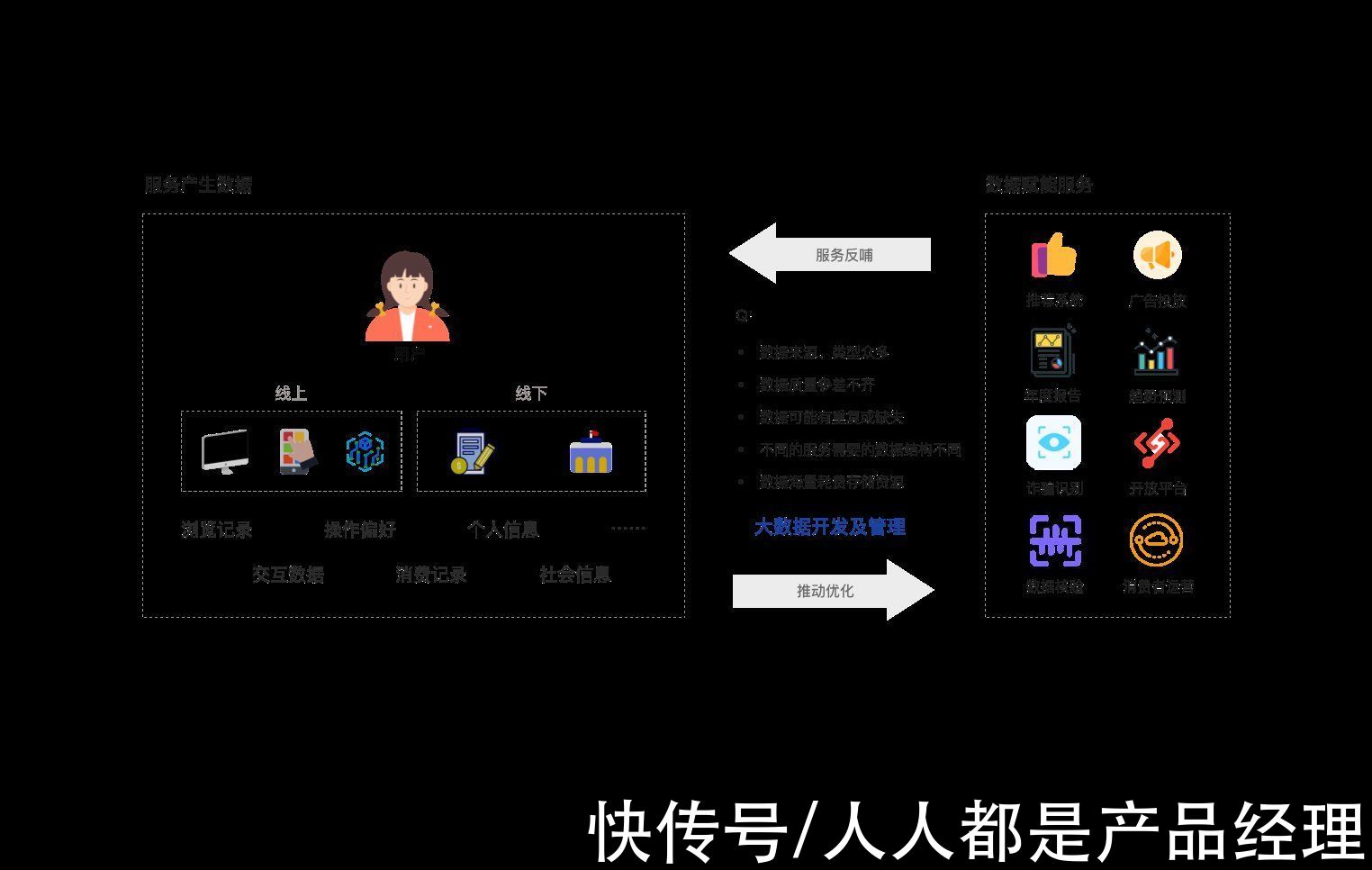
为了解决这类问题,需要构建“中间服务”——大数据开发及管理,通过提供统一的数据采集、处理与管理服务使数据达到“高质量”“高效率”“轻体量”的状态。
二、大数据开发与管理分几步
大数据开发与管理平台可分为5大模块:数据采集、整合计算、数据管理、数据安全与数据应用。
 1. 数据采集
1. 数据采集目的:将多源异构数据汇聚至数据湖中,等待下一步处理。
要做什么:
- 日志数据:对于日志数据可根据未来的分析需求与留痕需求进行埋点采集,通过使用User Track、Aplus.JS或一些自动化埋点工具结合相应规范进行采集。
- 其他数据库:对于其他数据库来源的数据需要根据对方数据库的参数进行配置建立采集任务,同时需要配置存储库表参数。
- 意外处理:对于以上两类数据,在采集过程中可能存在一些意外情况需要处理,例如:一些短时间内来自同一IP的高频访问可能是网络攻击,不能视为正常操作采集日志;在零点左右采集日志时可能发生数据漂移的情况;数据为null(无效值)需要剔除等。在图中列举了一些意外处理情况。
目的:对采集来的数据进行清洗、质检等操作。
要做什么:
- 模型设计:根据上层应用/分析需求进行数据模型设计,这里涉及三个维度的模型:维表(针对某一事物的描述,例如:会员数据、商品数据、店铺数据)、事实表(某一业务过程的描述,例如:商品收藏数据、下单数据)、指标数据(基于维表或事实表中的原子指标产生的派生指标,结合了时间周期、限定词等描述信息)。模型设计不仅要定义每个表中的字段还需要定义字段规则、更新时间等参数。
- 数据清洗/质量检测:根据字段映射关系与模型设计中的字段规则对数据进行清洗,根据清洗情况出具相应的质量检测报告。
- 任务调度:根据计算资源、实时性等因素对计算任务进行合理调度分配。
目的:对原始数据、经过处理的数据等资源进行分层管理,合理配置存储资源。
要做什么:
- 分层管理:对于不同阶段产生的数据需要分别进行管理,以便每一步处理留痕方便后续历史追溯。主要分为5部分:ODS(Operation Data Store 数据源头层)、DWD(Data Warehouse Details 数据细节层)、DWS(Data Warehouse Service 数据服务层)、ADS(ApplicationData Service 应用数据服务)、DIM(Dimension 维表层)。
- 存储成本管理:由于数据产生量巨大,同时还伴随需保留中间处理结果,所以存储成本需要进行相应控制,控制方式有4种:数据治理、数据压缩、数据生命周期管理、模型优化。
目的:将处理好的数据对外提供展开应用。
要做什么:
- 应用支撑:对于需要数据支撑的系统与模块提供服务。首先,需要对各维度进行模型构建,例如:商品、用户、会员等。建立描述完整的宽表;其次,需要梳理数据域、业务流程、各项原子指标与派生指标,定义各项指标口径,选择合适的模型构建方法(例如:雪花模型、星型模型)进行关联构建,构建好的专题库(也可称之为业务块)向上提供服务。
文章来源:《大数据》 网址: http://www.dsjzz.cn/zonghexinwen/2022/0227/3319.html